Home Price
Let's start with the fun part, enter the attributes of your home and call the API to get a predicition. If you're unsure of a value leave it blank and the model will impute the value based on the training dataset, but note that this will impact the precision of your estimate. Scroll below for more information on building this out.
Before you use this information to list your home for sale... read about the project below. There are many factors that influence the value of a home and not all were considered in this illustrative example of an ML system.
Building a Production Machine Learning System
Before you even begin...
The first rule of handling a problem is not to start with machine learning (ML). There may be easier, cheaper solutions that acheive similar results. At the very least, one should consider building the structure for a simple system and then adding in ML later, with more data.
Obtaining optimal data is one of the biggest challenges with any analytics project. I used the King County House Dataset for this, but there are no "datasets" in the real world. Just messy, unstructured, incomplete, biased data. There is an element of data engineering to every ML system.
Even with a tidy dataset for this illustrative project, there are still many enhancements that could be made. There is so much more that goes into the system than just the model. The point of this exercise for me was to develop the skills to build a ML system, not just a model, and this isn't a startup business for me.
With that, let's dive into the process. I used AWS Cloud Services, specifically, Amazon Sagemaker for this project.
Exploratory Data Analysis
We need to know what we have in the data we're working with. We can examine the columns, display the data distribution, identify null values, and review the correlation matrix. This helps us decide which type of model to use and which attributes have the most impact on the price of the house. It also helps us make a plan for how our model features may need to be transformed or encoded to work best in the model.
Let's take a look at an overview of the steps involved in a training pipeline.
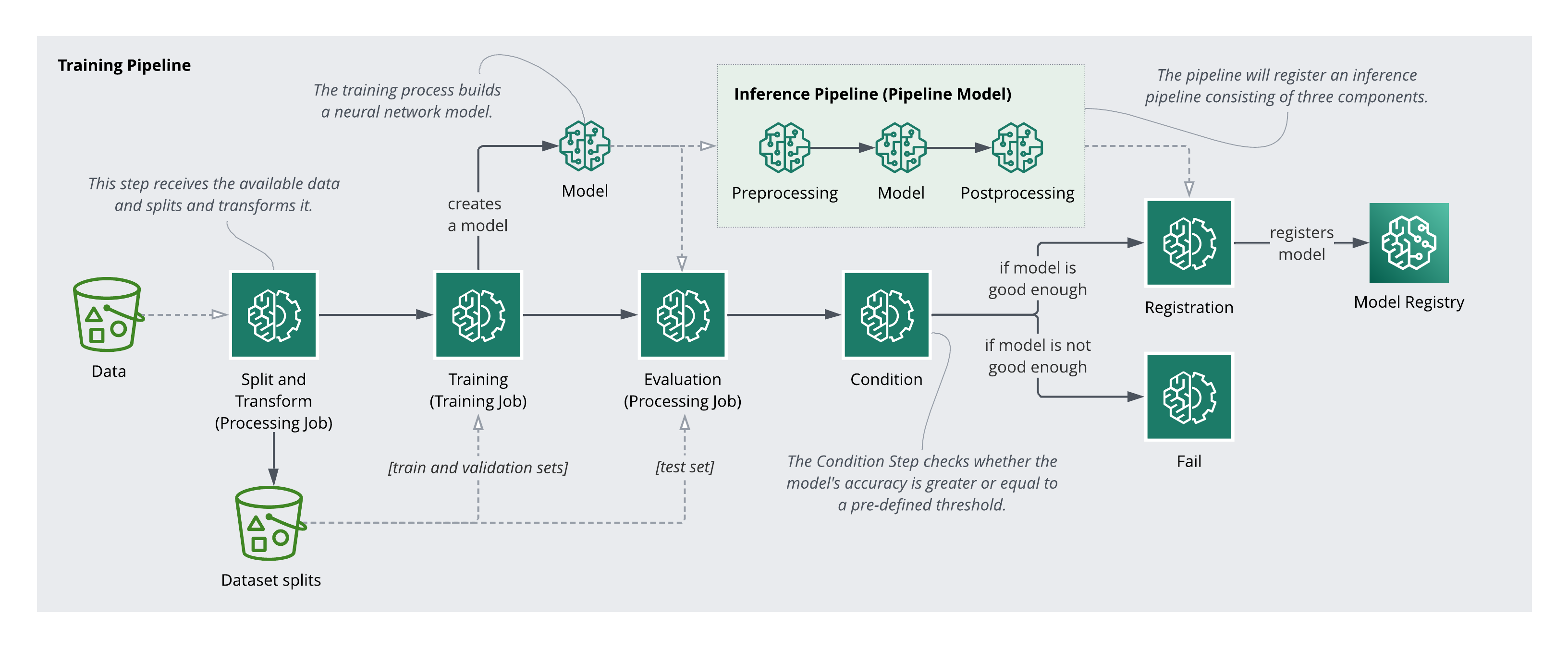 Overview of the training pipeline
Overview of the training pipeline
Preprocessing
I used a preprocessing pipeline to split and transformation the data. The splits are necessary for the training and evaluation, and the transformers will be used later after we train and deploy our model, as we will need to apply the same transformation to incoming data when serving predicitions.
Under the hood I used a Scikit-Learn Pipeline for the transformations, and a Processing Step with an SKLearnProcessor to execute a preprocessing script.
Training
Next comes the training step. This is an iterative process that involves lots of tweaks, data exploration, and going back to adjust the prepocessing. Much more could be written, but for the sake of brevity, a TensorFlow Keras Sequential Neural Network estimator was used to traing a regression model on a subset of attributes, and added as a Training Step to the pipeline.
Evaluation and Version
The model was evaluated on the test data set, and a deployment condition added as a pipeline step. This way, only models that perform adequately on data not seen during training can be registered. If the model meets the condition, the version is incremented and the model is registered with Amazon Sagemaker.
Deployment and Serving
Deployment involves packaging the pre and post processing into pipeline steps. What is provided and returned by the API must be transformed into a format that the nueral network model can ingest, including any encoding or scaling that was done. Once the full pipeline is configured an endpoint can be deployed, including any reviews and sign offs as necessary, and finally the model can be used to serve predictions.
Model Monitoring
Every model is a hero on day one, but it is important to monitor performance to catch drift. We must compare the endpoint traffic production data with the baseline data used to train the model to be able to monitor data drift. Additionally, the model performance can be monitored by comparing the endpoint predictions with some form of ground truth. This process involves labelling of some kind, but is critical to ensure the model performs well over time and can be retrained as needed.